前提としてpythonがインストールされていて利用できるものとします。
目次
まずはseleniumをインストール
pip install seleniumChromeを操作できるようにする
chromeを操作するために、自分のChromeのバージョンのchromedriverが必要です!
Chromeのバージョンを確認する
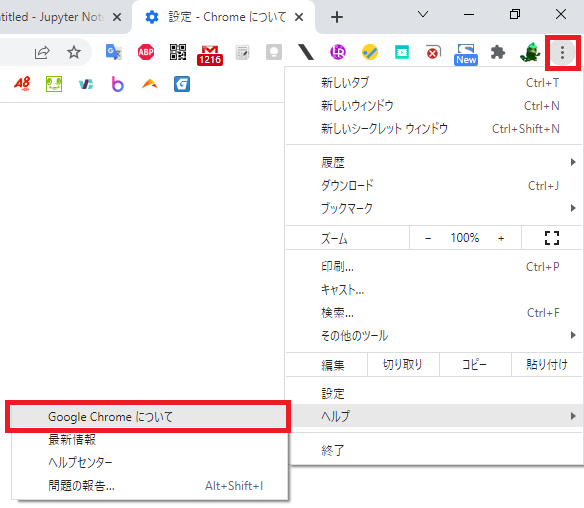
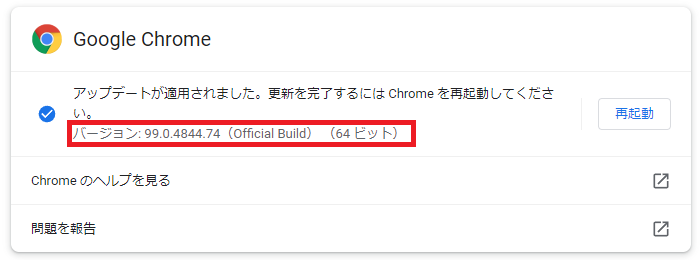
今回バージョンは99でした!
chromedriverをダウンロード
https://chromedriver.chromium.org/downloads
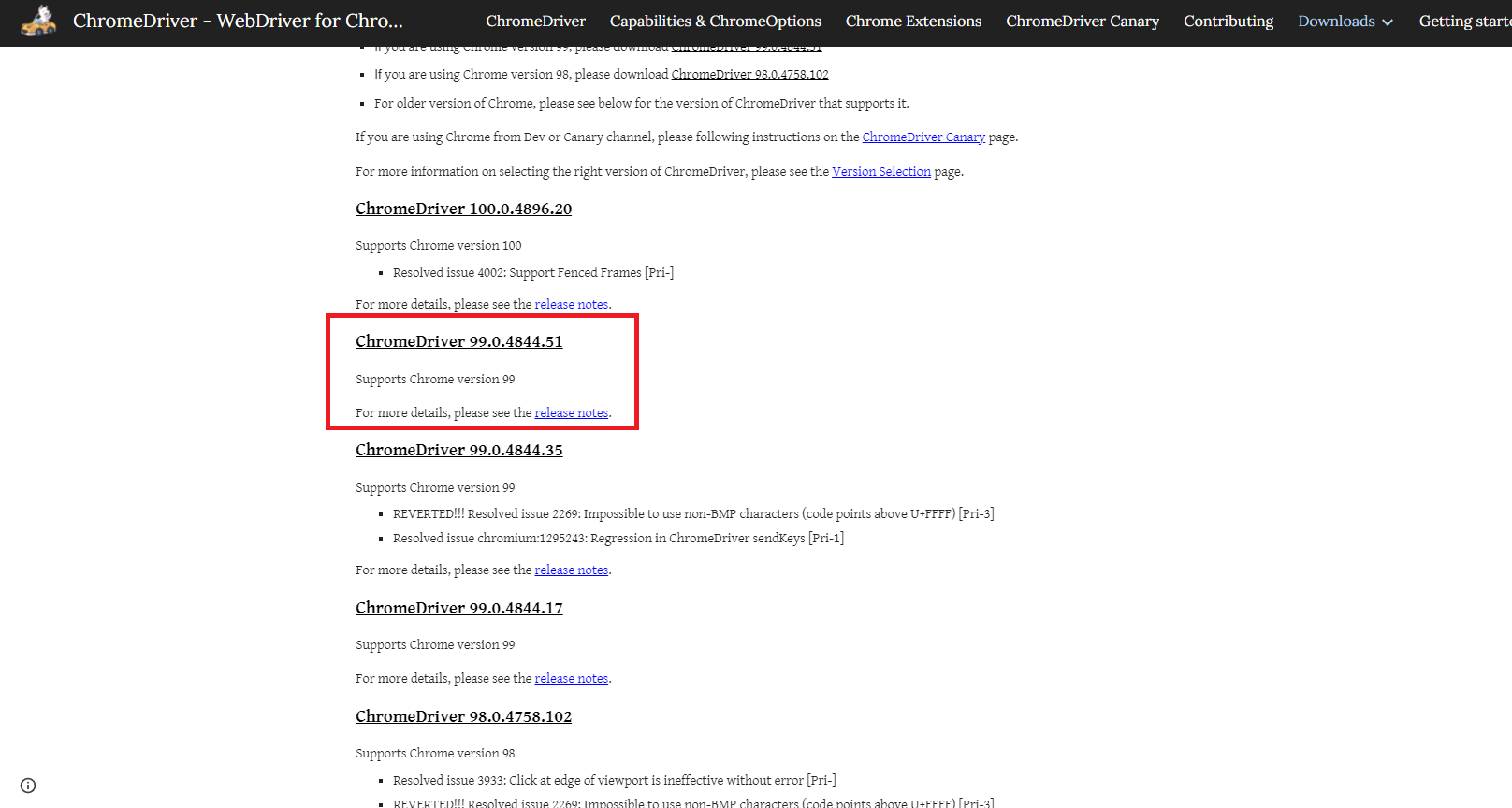
99の中で一番新しいものをダウンロードしました!
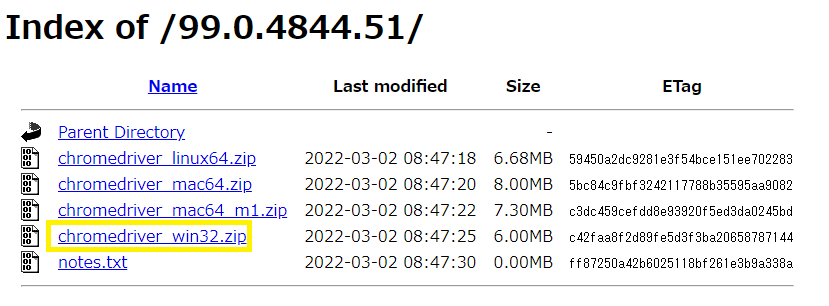
私はwindowsなのでchromedriver_win32.zipをダウンロードしました。
今回は、
ダウンロードしたzipは展開して中のchromedriver.exeをpythonファイルと同じ場所に置きました!
seleniumで特定のサイトを開いてみる!
from selenium import webdriver
chrome = webdriver.Chrome(executable_path='./chromedriver.exe')
chrome.get("https://417.run/")requestsを使ってダウンロードする
seleniumではダウンロードはできないようなので、requestsを使います!
import requests
# ダウンロード先フォルダ
path = './'
def download(url, filename):
urlData = requests.get(url).content
with open(path + filename ,mode='wb') as f:
f.write(urlData)seleniumで要素を探してループでダウンロード
from selenium import webdriver
chrome = webdriver.Chrome(executable_path='./chromedriver.exe')
# ダウンロードしたいものがあるページ
chrome.get("https://ssssssss")
# ダウンロードしたいテーブルを指定して、範囲を絞っている
element = chrome.find_element_by_id("tableidddddddddd")
# aタグを探す
atags = element.find_elements_by_tag_name("a")
for a in atags:
# hrefを取得して
href = a.get_attribute('href')
if href.find('.mp3') > 0:
# mp3であればダウンロード
download(href, href.split('/')[-1])